
Your AI coding assistant's identity is becoming an attack surface
PyTorch Lightning's compromise is the build-time twin of the AI gateway problem, and it lands inside India's procurement window.


On April 30, an attacker pushed lightning 2.6.2 to PyPI. Eighteen minutes later, Socket's research team flagged it. By the end of the day PyPI had quarantined the project. In the same window, a previously dormant GitHub account named pl-ghost, configured with maintainer-class permissions on Lightning-AI repositories, closed Socket's disclosure issue with a "SILENCE DEVELOPER" meme and ran six rapid create-and-delete branch operations across multiple Lightning-AI repos in roughly seventy minutes. Whether the publisher compromise and the GitHub-side compromise are the same actor or two opportunistic uses of overlapping stolen credentials is not yet established. What is established is that during the disclosure window, an account with elevated permissions on the project's own infrastructure was acting hostile to the disclosure process. The defenders against the next push were under adversarial control.
Earlier piece on the LiteLLM gateway compromise argued that the AI gateway is a credential vault sold as middleware. Today, the same argument extends one layer up, into the build-time training stack, because the same logic applies and the blast radius per host is structurally deeper. PyTorch Lightning is not an obscure dependency. It is the canonical PyTorch wrapper inside academic ML labs and enterprise ML platforms running inside Indian banks, telcos, and large GCCs. Many Indian ML teams use Lightning; exposure depth varies by team. The credentials that flow through a Lightning training host can be platform-tier rather than service-tier, and that gap is where today's escalation lives.
A Worm With Features
The Lightning compromise is not a bespoke campaign. It is the third stop in a three-package, two-ecosystem worm built from reusable parts. On April 29, SAP CAP framework npm packages were compromised by what Wiz, Mend, Sophos, and Onapsis all describe as a "Mini Shai-Hulud" variant of the original npm Shai-Hulud worm. On April 30, Lightning followed on PyPI, and intercom-client@7.0.4 followed on npm. All three share the same Bun JavaScript runtime fingerprint, the same GitHub-as-exfiltration channel, the same Dune-universe naming convention, and the same payload structure. Aikido and Safedep classify Mini Shai-Hulud as productized attacker tooling, not a one-off. The economics of supply-chain attacks have crossed the threshold where attackers maintain a code base and ship features to it.
The SAP CAP wing of Mini Shai-Hulud carries the most interesting structural finding for an AI publication, because it weaponized AI coding-assistant identities. Mend's analytical breakdown documents that the SAP CAP payload commits itself into every accessible GitHub repository by injecting a .claude/settings.json file that abuses Claude Code's SessionStart hook, plus a .vscode/tasks.json file with runOn: folderOpen so that any attempt to open the infected repository in VS Code or Claude Code re-executes the malware. The poisoned commits in the propagation chain were authored under a hardcoded identity impersonating Anthropic's Claude Code agent.
This is the first clearly documented case of an AI coding assistant's identity becoming attack surface.
AI coding assistants now commit code under recognizable identities, and developer-side trust signals about those identities ("Claude Code authored this") are starting to function as a soft authentication factor. As soon as that soft factor exists, it is an impersonation target. The closest available analog is the 2010-era browser-badge era, where the green "Verified by Verisign" or EV-SSL badge worked as a trust signal until certificate-issuance practices were compromised: the 2011 DigiNotar incident and the broader Symantec rogue-issuance era forced the browsers to stop treating the EV-SSL badge as a meaningful trust signal because the badge had become an attack surface. Any recognizable identity that travels with code into a project's history will eventually be impersonated, and the real defense is cryptographic provenance, not visual badges. SLSA (Supply-chain Levels for Software Artifacts), which defines a tiered framework for build-provenance attestations, and Sigstore, which provides keyless cryptographic signing with a public transparency log, are the technical answers. They are also far from universally adopted across the AI tooling stack.
The same finding applies inside training pipelines, with one twist. The build-time host does not just trust packages; it trusts agents that author commits, write configs, and edit Dockerfiles. As soon as Claude Code, Cursor, Codex, Cody, or any other commit-authoring agent develops a trusted identity inside a build pipeline, the agent's identity is part of the dependency graph.
Lightning on PyPI and SAP CAP on npm are two halves of the same lesson: the training stack now has to defend not only the packages it imports but the agents that wrote the configs that imported them.
The Eighteen Minutes
Half a dozen security firms in the same window converge on the same picture. Socket, Aikido, Semgrep, Snyk, and Safedep all report the following. Versions 2.6.2 and 2.6.3 of the canonical lightning PyPI package were published on April 30. They carry a hidden _runtime directory containing a downloader and an obfuscated 11 MB JavaScript payload that activates automatically on import lightning. The runtime is Bun, the same JavaScript runtime fingerprint that has now appeared in three Mini Shai-Hulud compromises across two ecosystems in 48 hours.
The payload exfiltrates SSH private keys, shell history, AWS, GCP and Azure credentials, GitHub and npm tokens, and cryptocurrency wallets.
Exfiltration runs through GitHub itself: the malware uses any stolen GitHub token to create public repositories named with two words from the Dune universe, with the description "A Mini Shai-Hulud has Appeared," and pushes the harvest into them.
Socket flagged the package eighteen minutes after upload. PyPI quarantined it the same day. The GitHub Security Advisory GHSA-w37p-236h-pfx3 confirms the compromise. Eighteen minutes is fast for an automated detector and slow for a package this widely automated, where CI runners, Dockerfile builds, and scheduled training-environment refreshes ingest new versions without human approval. Quantitative install data for the in-window period is not yet published; the conservative read is that the catchment is non-zero and probably significant.
Why the Vault Moved
The earlier piece argued that a single row in litellm_credentials typically holds an OpenAI organization key, an Anthropic console key, an AWS Bedrock IAM credential, and the proxy runtime config. The AI gateway concentrates LLM provider credentials and a handful of cloud-runtime keys into a Postgres row that gets read on every request.
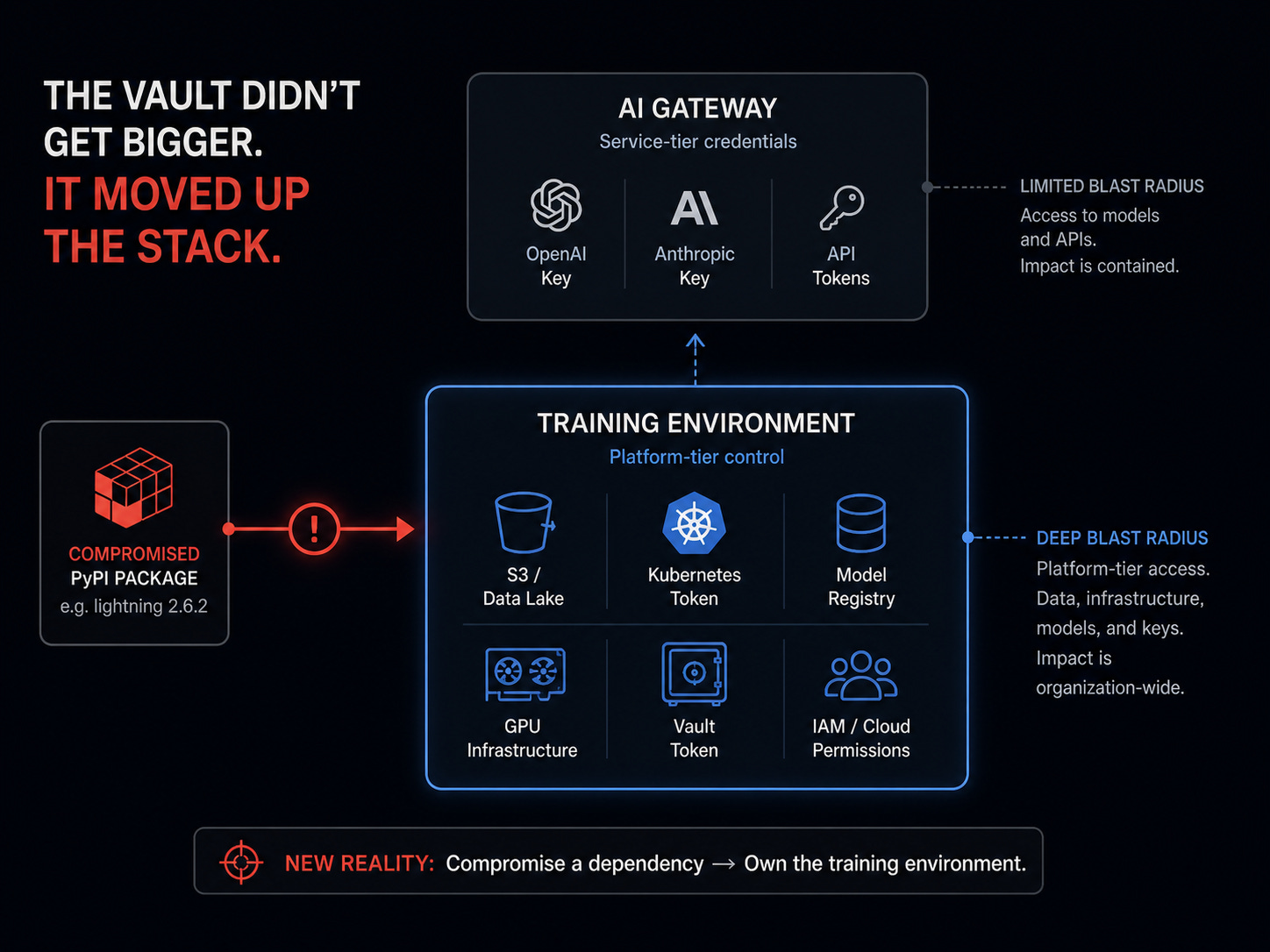
The training-stack picture is different in kind
A typical Lightning training host can carry credentials that are platform-tier rather than service-tier:
the data-lake S3 IAM role with read access to the petabyte the model is being trained on;
the GPU-instance launch credential with permissions to spin up multi-hundred-thousand-dollar reservations;
the model registry write credential, which lets you push checkpoints into the same registry that production inference reads from;
the Kubernetes ServiceAccount token, which lets the training pipeline talk to the rest of the cluster; and
increasingly a HashiCorp Vault token, since training pipelines pull short-lived secrets the same way production services do.
Coverage of the parallel intercom-client@7.0.4 npm wing of the Mini Shai-Hulud campaign on April 30 reports an expanded credential harvest including Kubernetes ServiceAccount tokens and HashiCorp Vault credentials, suggesting the attacker has internalised that the build-time host holds these.
The specific credential set varies enormously by organisation. The argument applies most strongly to training hosts that share IAM with the broader ML platform, which is the default in most orgs that have grown an ML platform from a single-team data-science setup. Mature ML platforms with strict role separation between training, registry, and serving have a smaller blast-radius gap. The escalation is conditional on ML-platform maturity, but a sizeable fraction of the install footprint sits at organisations that have not yet built that separation.
Where the escalation does apply, it is qualitative. A compromised gateway lets the attacker spend the customer's OpenAI quota and read the prompts that flow through it. A compromised training host can let the attacker read the training data, write the checkpoint, push the registry, and stand up new GPU capacity in the victim's cloud. Checkpoint poisoning is a path a sufficiently motivated adversary could walk; the current Mini Shai-Hulud payload does not appear to take it. Catalogued payloads to date harvest credentials and tokens rather than tamper with checkpoints. The capability is structurally present; whether it is exercised depends on the adversary's objective.
The empirical anchor for "AI is now infrastructure" is the Wiz Cloud Threat Retrospective 2026, published in the same April window. Two numbers matter for this argument:
90% of cloud environments now run self-hosted AI software, and
68% of organisations running self-hosted models ingest them through third-party software.
When a single PyPI dependency sits inside that distribution, "build a training pipeline" is no longer just a developer-tooling decision. It is a security architecture decision.
The Adjacent Surface: Model Registries
Trusted Publishing addresses the publishing-pipeline failure mode the Lightning incident exposed. It does not address the parallel attack surface that has been an active research target for two years: model registries themselves. Hugging Face has documented multiple campaigns of malicious model uploads using pickle deserialisation, executable artifacts disguised as weight files, and supply-chain insertions through derivative model trees. JFrog and Protect AI have both published threat-model work on model-registry attacks; the OWASP Top 10 for Large Language Model Applications includes model-supply-chain risk as a discrete category. For an India-forward piece this matters because the IndiaAI Mission's compute-and-models stream explicitly contemplates model hosting alongside compute provisioning. A procurement clause that addresses Trusted Publishing for the Python wheels but not provenance for the model artifacts that travel through the same pipeline solves half the problem. Both surfaces deserve coverage in any serious supply-chain audit.
The Defender Anthropic Is Selling
There is an instructive irony inside the same forty-eight hours. On April 30, Anthropic launched Claude Security in public beta, an Opus 4.7 vertical SKU that scans codebases for vulnerabilities and generates targeted patches. CrowdStrike, Palo Alto Networks, SentinelOne, Trend Micro, and Wiz simultaneously announced integrations of Opus 4.7 into their cybersecurity platforms. The product targets the long-tail vulnerability class that legacy SAST tools miss.
But the maintainer-credential takeover pattern that hit Lightning is precisely the class of attack codebase-scanning AI cannot detect. The malicious code did not arrive through a code change in the repository. It arrived through a publishing channel, on top of a maintainer credential that had been stolen out of band, with no source-code review touchpoint at all. Claude Security can read the Lightning repository at HEAD all day long and find nothing wrong. The bad wheel never lived there. This is not a criticism of Claude Security; it is a comment on the structure of the threat. Most of the AI-powered defender tooling shipping in 2026 is tuned for code-resident vulnerabilities; the attack pattern that has won the last forty-eight hours is identity- and credential-resident, in the publishing layer above the code.
Closing this gap is not a matter of better models. It is a matter of putting cryptographic provenance into the publishing pipeline so that an agent scanning a repository can verify "this wheel was published from a CI run authorized by a maintainer with these properties" rather than just "this wheel exists." The work is in flight. It is also the structural mitigation the Lightning incident points to.
But isn’t This Already Solved By Pinning and SBOMs
The strongest counter-case to today's piece runs as follows. Software supply chain risk is not new; it predates AI.
The mitigations are known and deployed:
dependency pinning,
lockfiles,
SBOM generation,
signature verification,
mirror-and-vendor patterns inside enterprise build systems.
A mature ML platform that uses pinned hashes in its requirements.txt, pulls from an internal Artifactory mirror with quarantine and scanning, and has Software Composition Analysis (SCA) tooling running on every build will simply not install lightning 2.6.2 until that version has cleared internal review.
The Lightning compromise hits hobbyist installs and immature CI pipelines. Mature shops are fine.
The case is not theoretical.
Anaconda's curated default channel runs human review on the package set it ships.
Red Hat's Universal Base Image Python builds restrict the trusted set to packages that pass Red Hat's own provenance audit.
Google's Borg-era vendoring approach pulls every external dependency into an internal mirror, hashes it, and rebuilds from source under a separate trust boundary; the same model has been ported into many of the largest tech employers' internal Bazel builds.
Each of these models is designed to stop a class of compromise like Lightning 2.6.2; whether any of them would have caught this specific version on April 30 depends on the timing of internal-mirror sync and review cadence. The pinning-and-mirroring playbook is real and works at the population level it was designed for.
The case is half right and worth steelmanning honestly. The mature shops do have these controls. The proportion of training pipelines that meet that bar across the broader AI ecosystem, including most academic ML labs, most early-stage AI startups, most GCC AI teams that picked up Lightning in the last twelve months, and a meaningful fraction of enterprise data-science groups, is much smaller than the proportion that ought to. The Wiz numbers above are consistent with the second reading: ninety percent self-hosted AI penetration with sixty-eight percent of those models pulled through third-party software is not a description of an ecosystem where mature shops dominate the population.
There is a further wrinkle. Even pinned-hash builds depend on the upstream package having been published from a credential-controlled pipeline, because the hash you pin to was produced by that pipeline. If the upstream maintainer credential was compromised, the bad wheel got a hash too, and you pinned to it. The structural mitigation has to land at the publishing pipeline, not only at the consumer.
Steelman Two: Procurement Theatre
A second steelman is harder and worth naming. Each new supply-chain compromise is followed by a wave of procurement-clause demands that impose compliance burden on the immature shops least able to absorb it, while doing little to alter the incentive structure of the attackers. Trusted Publishing as a procurement-audit clause might land as a checkbox that vendors fill in by configuring the minimum-viable OpenID Connect (OIDC) workflow on a private fork, with no actual change in publishing posture. India has recent experience with compliance clauses that became costly forms-filling exercises rather than security improvements. The honest version of the close has to address why this clause is different.
The thinner answer is that Trusted Publishing is not an attestation of intent; it is a verifiable property of the publishing identity, mechanically checked at the time the package is uploaded. A CERT-In or MeitY auditor can independently confirm whether lightning on PyPI was published under Trusted Publishing without trusting the vendor's word. The fatter answer is that procurement clauses change incentive structures slowly, and the goal is not to fix the immature half of the ecosystem in six months. It is to make the structural mitigation a default expectation in the next five years of Indian AI procurement, the way SOC 2 became a default expectation across SaaS procurement in the 2010s. Theatre is a real risk; verifiability and time horizon are the responses.
Trusted Publishing as a Layered Mitigation
PyPI Trusted Publishing replaces long-lived API tokens in maintainer hands with OIDC-exchanged short-lived publishing tokens, typically valid for fifteen minutes, issued from a configured CI provider workflow against a verified identity. The trust anchor moves from "what the maintainer holds in their .pypirc" to "what GitHub Actions, GitLab Self-Managed, Google Cloud Build, or any other configured OIDC issuer can prove about the publishing job." If the maintainer's PyPI token is stolen, there is nothing to steal, because there is no long-lived token to steal. The attacker would need to compromise the CI provider's OIDC issuer or the configured publishing workflow itself, which is materially harder.

It is worth being precise about what Trusted Publishing addresses and what it does not. It is a structural mitigation for the specific class of attack that hit Lightning: maintainer-credential takeover at the publishing layer. SBOM generation, signed provenance via Sigstore, and a vendor commitment to timely security updates are layered controls that the EU Cyber Resilience Act and OpenSSF best-practice guidance already require alongside it.
The adoption picture is moving in the right direction. PyPI introduced Trusted Publishing in April 2023; over 13,000 projects had voluntarily adopted it by mid-2024 (OpenSSF guide); by the PyPI 2025 year-in-review, the figure was over 50,000 projects, with more than twenty percent of all PyPI file uploads in 2025 going through Trusted Publishing, and over a million files cumulatively published through it as of September 2025. npm Trusted Publishing shipped in 2025 and is built on the same OIDC pattern. RubyGems shipped one in December 2023. The structural answer is in production and widely deployed.
PyTorch Lightning, at the time of the April 30 compromise, was not on Trusted Publishing. That is not a criticism of the maintainers; large mature open-source projects have decade-old release scripts and custom infrastructure that does not migrate cheaply. It is an observation about the gap between "the structural mitigation exists" and "the most consequential AI/ML packages have adopted it."
The Indian Procurement Window
There is a specific institutional window in India that opens now. CERT-In's late-April 2026 advisory cadence has remained heavy on healthcare ERPs and conventional CVE notifications, but has not yet covered AI-stack supply chains as a discrete category. By my read, no public Indian procurement template requires PyPI Trusted Publishing or equivalent OIDC-bound publishing for AI/ML packages above any download threshold. There is no published Indian SI standard that conditions GCC build-pipeline ingest on signed provenance. There is no IndiaAI Mission compute-subsidy clause that gates GPU-time on Trusted-Publishing-configured upstream dependencies.
The institutional path runs across three offices.
CERT-In has the standing to issue a sectoral advisory naming AI/ML supply-chain compromise as a discrete threat class and recommending Trusted Publishing as a structural mitigation.
MeitY has the standing to fold that recommendation into its empanelment criteria and procurement-template guidance.
The IndiaAI Mission has the standing to incorporate Trusted-Publishing-configured upstream dependencies as a scored axis in its GPU-subsidy procurement round. The advisory step is realistically a four-to-six-week effort. The procurement-template revision is six-to-nine months. The empanelment-criteria update is somewhere between, depending on cycle timing.
The precedents exist. CERT-In has published sectoral advisories on cloud, on cryptographic libraries, and on critical infrastructure CVEs. MeitY has revised empanelment criteria multiple times in response to changes in the threat landscape. The IndiaAI Mission has incorporated security-related scoring axes in earlier procurement rounds. Indian SIs anchored by TCS and Infosys, which together carry the largest GCC AI staffing footprint across Bangalore, Hyderabad, Pune, and Chennai, set internal audit clauses that become de facto standards for the Global Capability Centers (GCCs) build pipelines they support; that creates a private-sector amplification path once the public-sector recommendation lands.
The multilateral check matters because India is not legislating in isolation. The EU Cyber Resilience Act imposes SBOM and vulnerability-handling requirements on "products with digital elements" by December 2027, capturing AI/ML packages by definition. The US has Executive Order 14028 directing federal agencies toward signed provenance via Sigstore and SLSA. Two specific forums matter most for India.
The Quad Cybersecurity Partnership has a working stream on supply-chain integrity that has named software supply chains as a designated focus area in recent ministerial readouts; AI-stack supply chains fit naturally inside that scope and have not yet been named explicitly, which is the gap an Indian advisory could help close.
The India-Japan AI Strategic Dialogue, which has met twice in the last twelve months, has touched on critical-software designation under Japan's Economic Security Promotion Act; coordinating on Trusted-Publishing-equivalent requirements would be a defensible bilateral ask.
The Indian gap is not that the international consensus is unclear. The gap is that the Indian regulatory layer has not yet operationalised any of it for AI specifically.
What Falsifies This Argument
A few honest counters. The piece would be wrong, in directional or structural ways, if any of the following played out over the next two quarters.
First, if Q3-Q4 2026 sees a major AI-stack supply-chain breach traced to a Trusted-Publishing-configured upstream where the OIDC issuer or the configured CI workflow was the attack surface, the procurement-audit case weakens significantly. Trusted Publishing is a good mitigation against the maintainer-credential-takeover class, not a cure-all. A demonstrated bypass would change the procurement story.
Second, if the next major breach traces to a non-publishing vector, for example a model-weight tamper attack inside Hugging Face, an inference-server escape inside vLLM or SGLang, or an upstream compromise in a transitive Python dependency that Lightning happens to import, the "vault moved up the stack" framing is incomplete. The attack surface is plural, and Trusted Publishing only covers one face of it.
Third, if Indian regulators move on something other than a procurement-audit clause (a softer SBOM-recommendation, a voluntary attestation, or a mandatory disclosure-window rule), the actionable close is wrong even if the diagnosis is right. The institutional path matters, and CERT-In or MeitY may simply choose differently.
Closing
The single sentence that does not yet appear in any procurement document, and probably should: "Above a defined download threshold, AI/ML packages used in regulated training pipelines must be published under PyPI Trusted Publishing or an equivalent OIDC-bound publishing identity, with attestation verifiable by the procuring entity." Eighteen minutes is a short detection window.
Procurement clauses, by contrast, take six months to land, and that is the path with the most leverage and the longest tail. The right time to start is today.